
Short explainer. Deploy federated learning at the edge with EdgeLake. Models move between nodes, data stays in place at each site.
This short explainer walks through what federated learning is and how EdgeLake automates the entire setup, using a hospital analogy that maps directly onto industrial deployments.
Centralized machine learning needs every participating entity (hospital A, B, C in the canonical example) to ship its raw data to a single training infrastructure. That data move is what makes federated learning attractive. Instead of moving the data, each hospital trains a local sub-model on its own data, and only the model parameters travel to an aggregation server. The aggregator fuses the sub-models into one and pushes it back. Raw data never leaves the institution, and continuous learning keeps improving the global model as new local observations arrive.
For industrial systems, the same pattern applies. A machine builder can collaborate with its machine-operator customers to train a predictive-maintenance model across many sites without anyone exposing their operational data to the others.
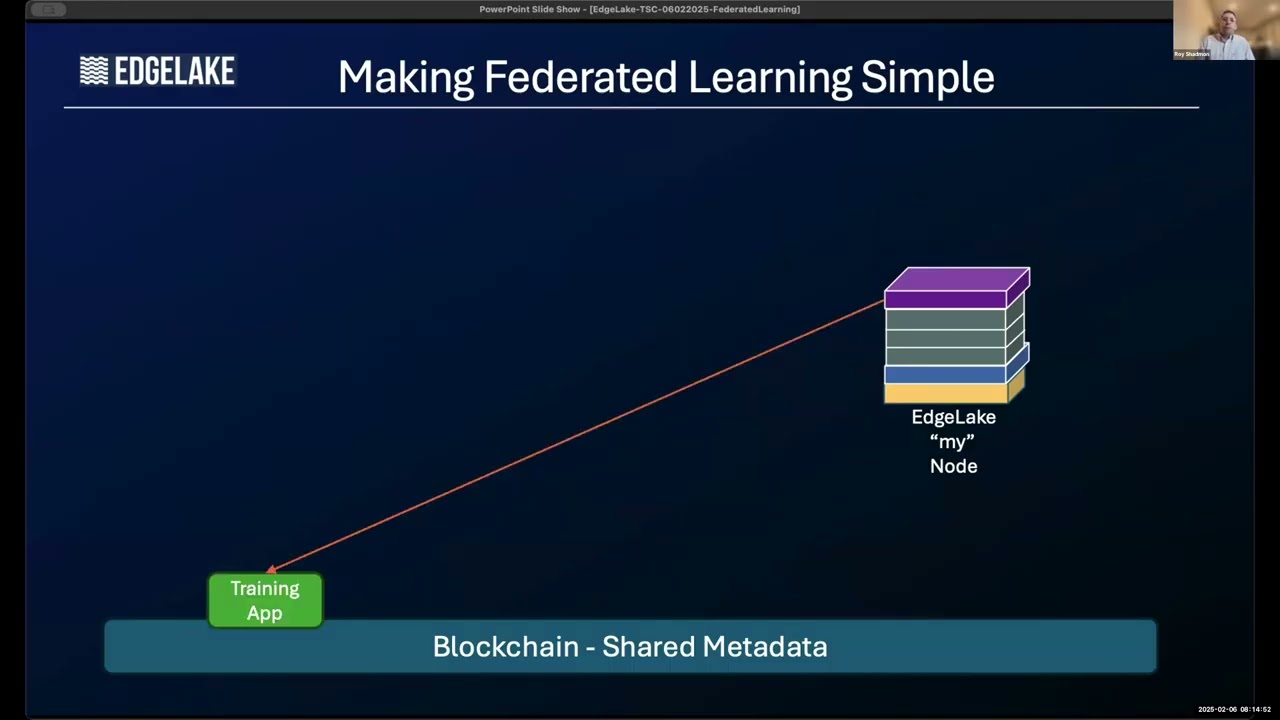
The EdgeLake automation is the punchline. Publish the training application onto the shared metadata layer (the blockchain layer EdgeLake nodes already use for policies). Every relevant operator node picks it up, runs training against its local database, and publishes its sub-model back to the metadata layer. An aggregator node pulls the sub-models, builds the final unified model, and republishes it. Inference applications on each edge node then pull the final model and run predictions locally, producing control outputs in place. No data movement; just policies and models traveling across the fabric.